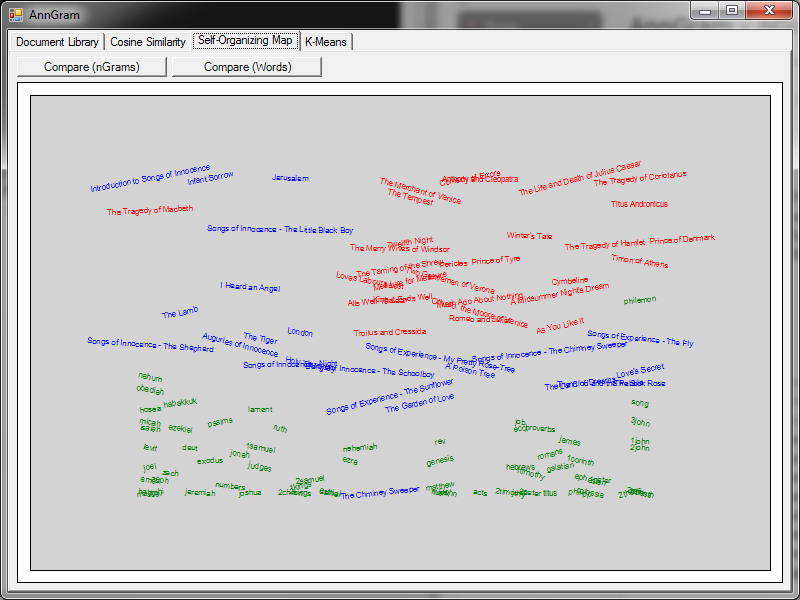
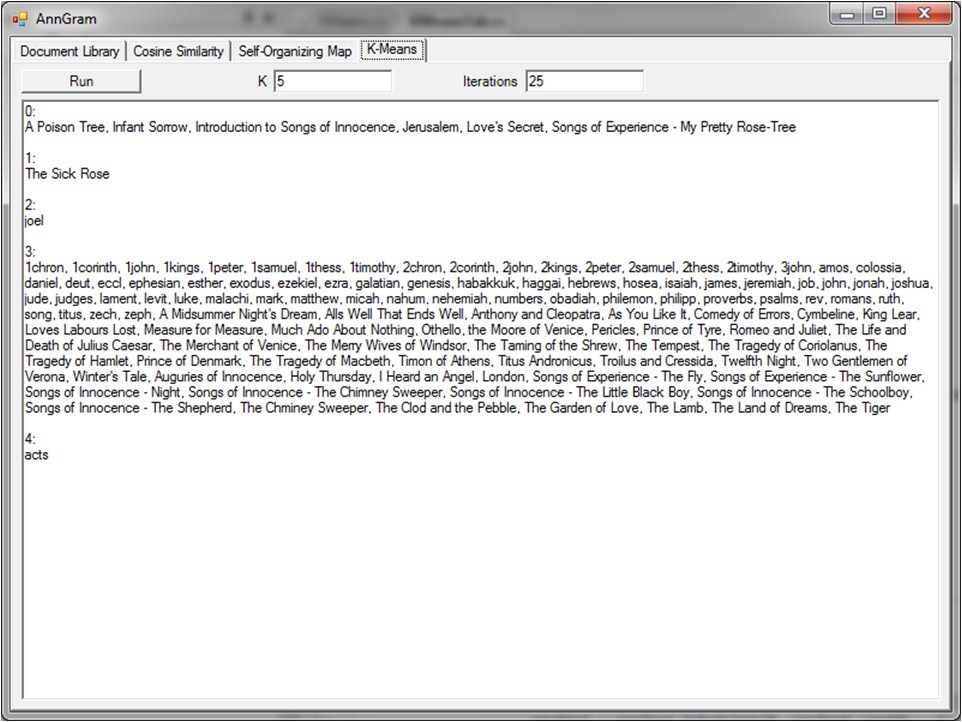
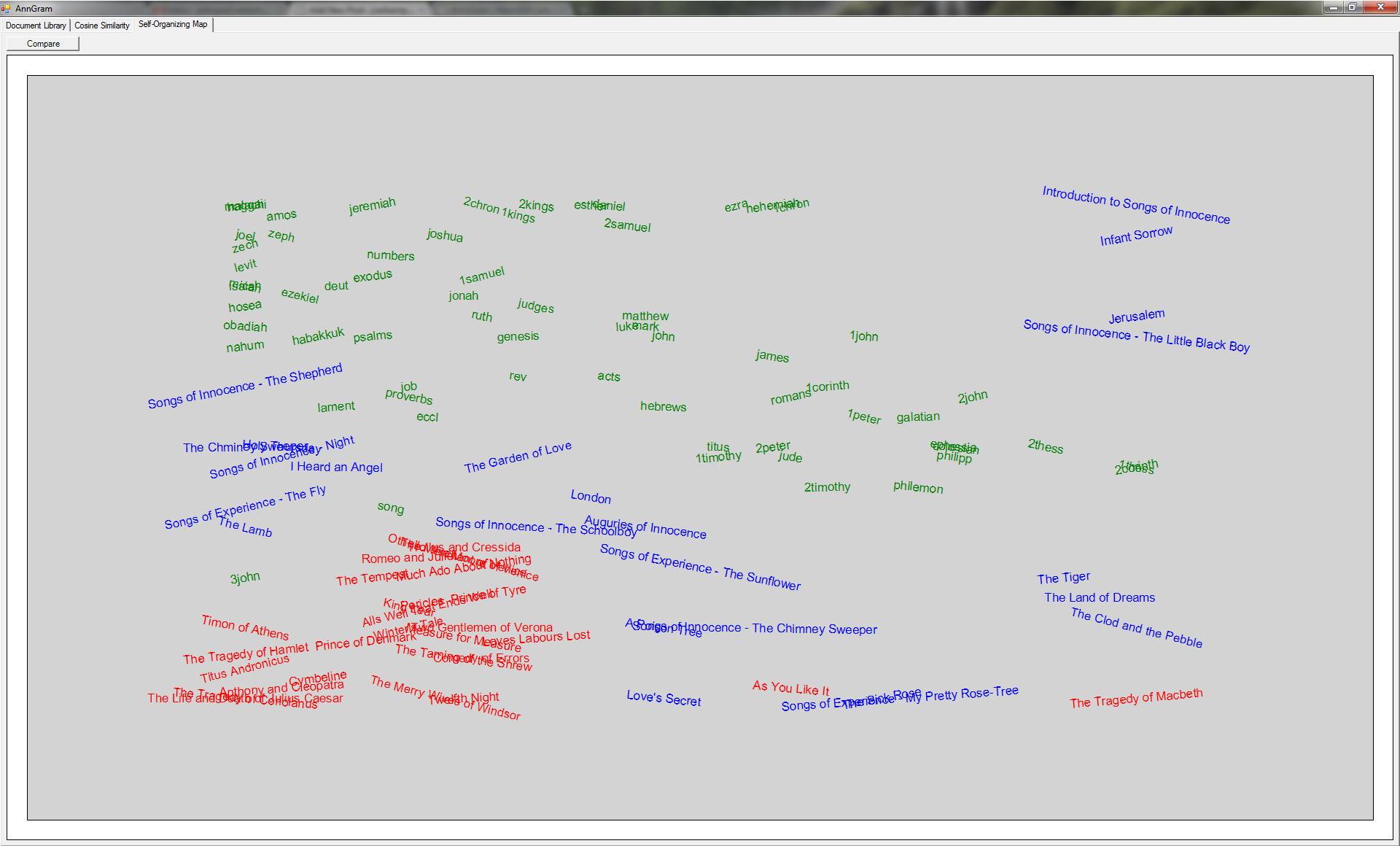
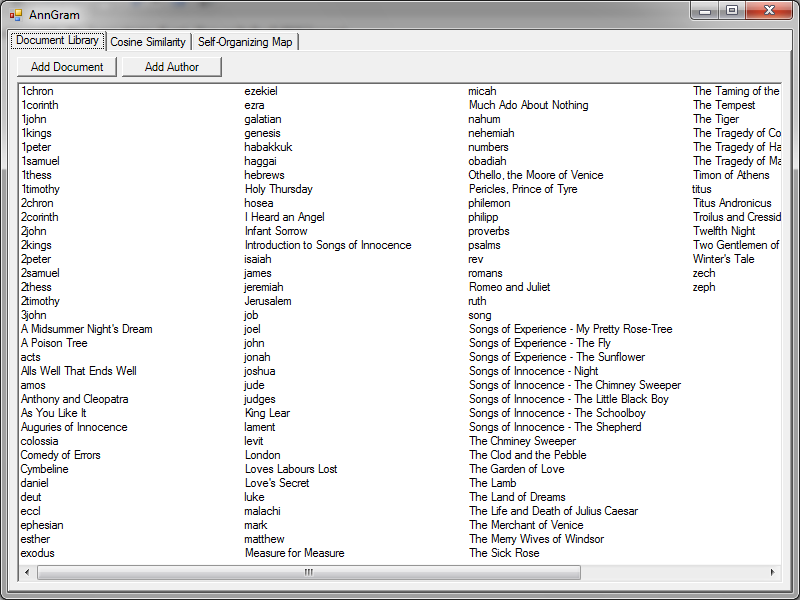
Once upon a time, I was on track to get a PhD in censorship/computer security. I was ABD (all but dissertation) when my advisor decided to leave and go into the private sector. When that happens… you either find a new advisor or you go with them. I decided to go with them, move to Silicon Valley, and join a startup. It was perhaps the best thing that could have happened to me. While I sometimes regret not having the extra letters after my name, I love the practicality of working in the ‘real world’. Not to mention the job prospects are better. :)
So for the most part, these posts are archival, but there are still a few gems in there.