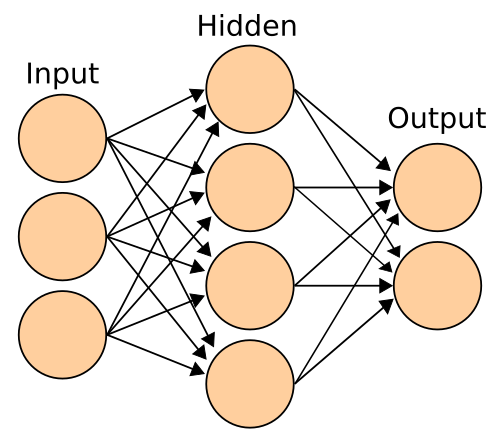
Overview
The first algorithm that I’ve chosen to implement is a simple cosine difference between the n-gram vectors. This was the first method used in multiple of the papers that I’ve read and it seems like a good benchmark.
Essentially, this method gives the similarity of two n-gram documents (either Documents or Authors) as an angle ranging from 0 (identical documents) to \pi/2 (completely different documents). Documents written by the same author should have the lowest values.