Overview
For now, I’ve chosen to work with C# Neural network library. It was the easiest to get off the ground and running, so it seemed like a good place to start.
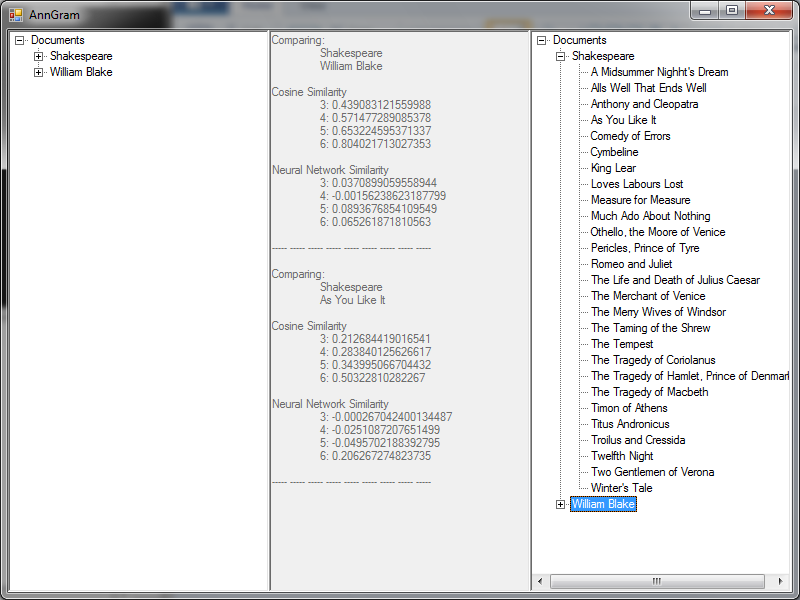
Overview
For now, I’ve chosen to work with C# Neural network library. It was the easiest to get off the ground and running, so it seemed like a good place to start.
I’ve been looking for a good Neural Network library to use with the AnnGram project and so far I’ve come across a couple of possibilities:
The top link on Google was an aptly named C# Neural network library. Overall, it looks clean and easy to use and is licensed under the GPL, so should work well for my needs. The framework has two types of training methods: genetic algorithms and backward propagation. In addition, there are at least three different activation functions included: linear, signmoid, and heaviside functions. The main problem with this framework is the spare documentation. The only that I’ve been able to find so far is a generated API reference and a few examples (using their included GUI framework).
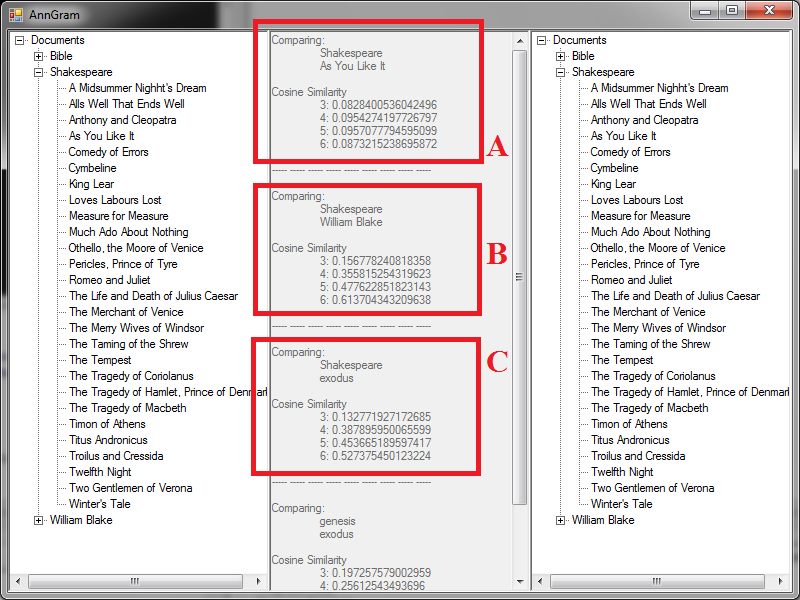
Overview
Basically, I got tired of modifying the command line every time I wanted to test new values. To that end, I spent a small bit of time coding up a GUI to make further experiments easier.
Overview
The first algorithm that I’ve chosen to implement is a simple cosine difference between the n-gram vectors. This was the first method used in multiple of the papers that I’ve read and it seems like a good benchmark.
Essentially, this method gives the similarity of two n-gram documents (either Documents or Authors) as an angle ranging from 0 (identical documents) to \pi/2 (completely different documents). Documents written by the same author should have the lowest values.
Document Framework
The first portion of the framework that it was necessary to code was the ability to load documents. To reduce the load on the processor when first loading the document, only a minimal amount of computation is done. Further computation is pushed off until necessary.
To avoid duplicating work, the n-grams are stored using memoization. The basic idea is that when a function (in this case, a particular length of n-gram) is first requested, the calculation is done and the result is stored in memory. During any future calls, the cached result is directly returned, greatly increasing speed at the cost of memory. Luckily, modern computers have more than sufficient memory for the task at hand.
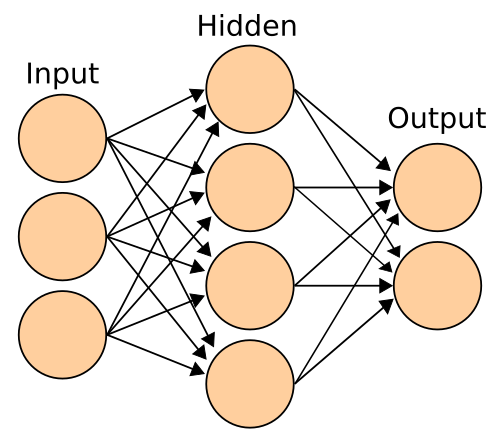
Basic Premise
For my senior thesis at Rose-Hulman Institute of Technology, I am attempting to combine the fields of Computational Linguistics and Artificial Intelligence in a new and useful manner. Specifically, I am planning on making use of Artificial Neural Networks to enhance the performance of n-gram based document classification. Over the next few months, I will be updating this category with background and information and further progress.
First, I’ll start with some basic background information.