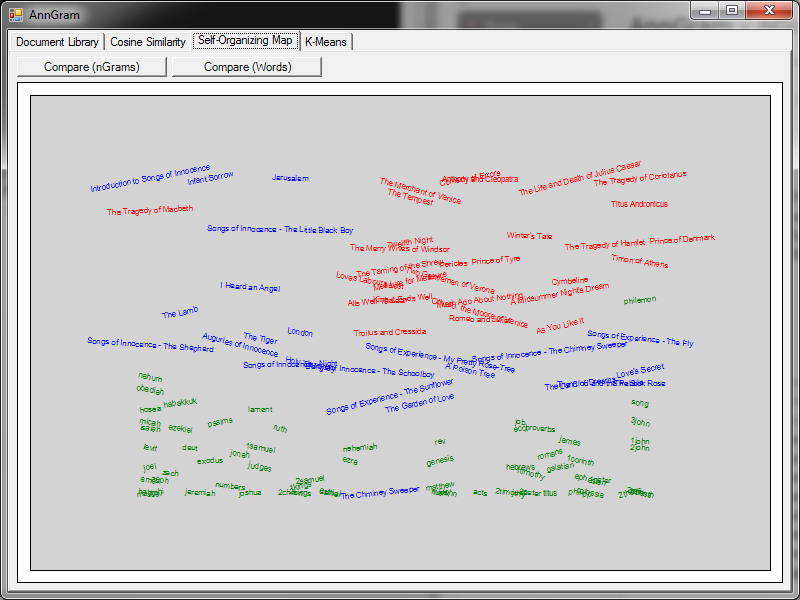
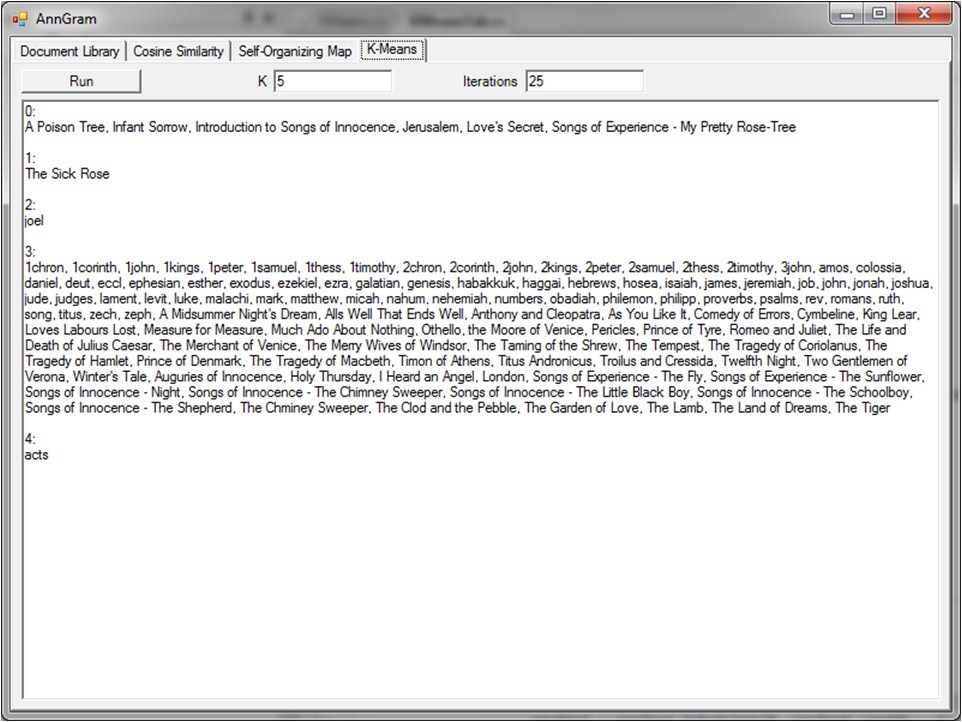
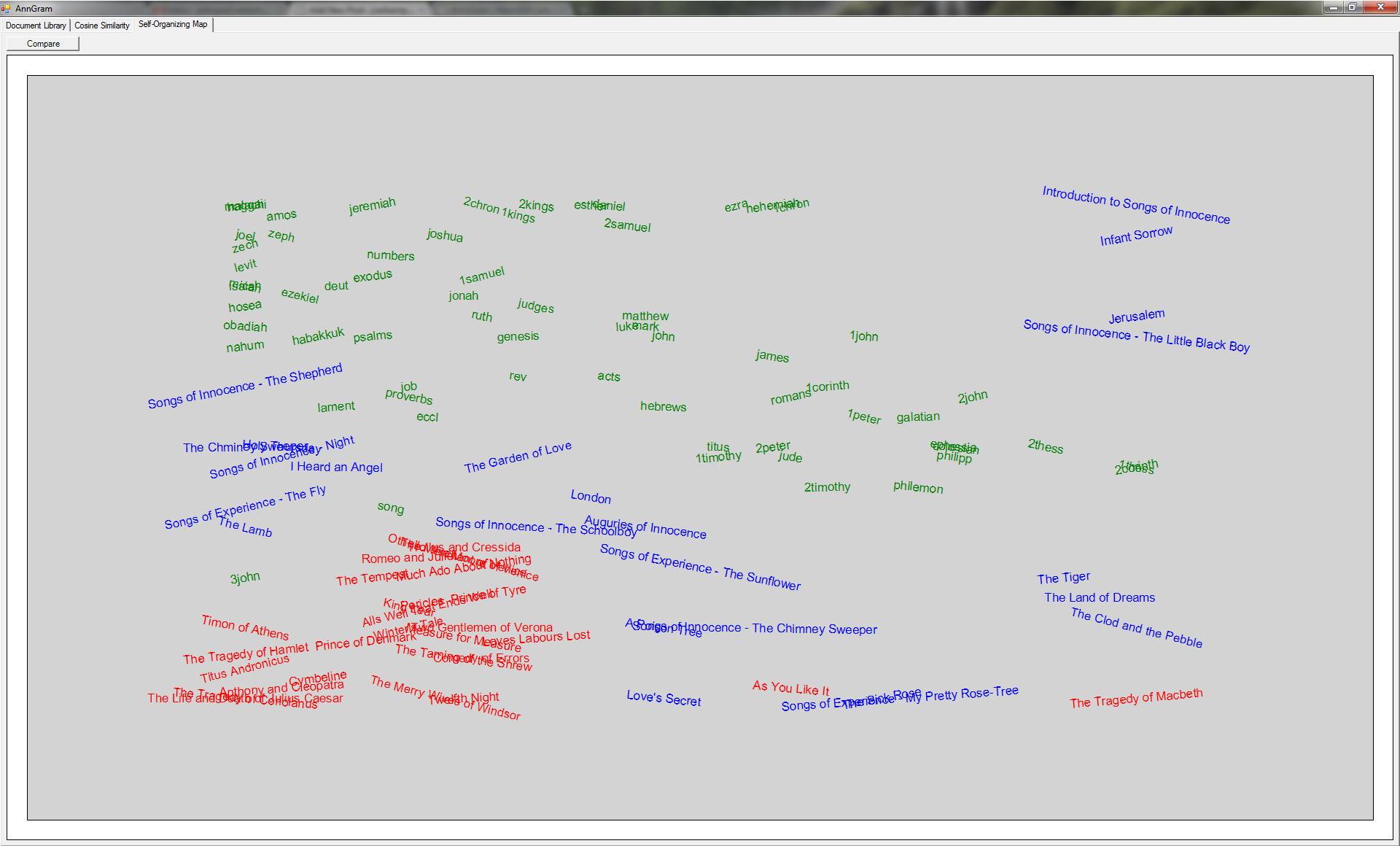
So far, we’ve had three different ideas for figuring out the author of an unknown paper (top n word ordering in Part 1 and stop word frequency / 4-grams in Part 2). Here’s something interesting though from the comments on the Programming Praxis post:
Globules said July 19, 2013 at 12:29 PM Patrick Juola has a guest post on Language Log describing the approach he took.