At the moment, I have an Apple Music subscription. It’s great to be able to listen to more or less whatever music I want to. I switched from Spotify because they were missing a few artists that I actually did want to listen to. Unfortunately, there are a few things that Apple Music doesn’t do that I would like to have–chief among them the ability to play on a Roku.
One nice thing that Spotify does have though is a fairly powerful API: Spotify Web API. Inspired by a post on Spotify and billboard.py which automatically creates Spotify playlists from the Billboard music ranking charts, I decided to write up a script that can sync my playlists from iTunes to Spotify.
First, let’s write a method that uses the Spotify web API to search for tracks (or actually any type, such as an artist):
@memory.cache
def spotify_search(type, retries = 3, **params):
'''Search for an item on the spotify API.'''
logging.debug('spotify_search({}, {})'.format(type, params))
url = 'https://api.spotify.com/v1/search'
query = ' '.join(
'{key}:{value}'.format(key = key, value = params[key])
for key in params
)
response = requests.get(url, {'type': type, 'q': query})
if response.status_code == 419:
timeout = int(response.headers['Retry-After'])
sys.stderr.write('Rate limited, waiting {} seconds...\n'.format(timeout))
time.sleep(timeout)
return spotify_search(type, retries = 3, **params)
if response.status_code != 200:
if retries:
logging.warning('Non-200 status code for {}, retrying in 1 second...\n'.format(query))
time.sleep(1)
return spotify_search(type, retries = retries - 1, **params)
else:
logging.critical('Non-200 status code for {}, no more retries'.format(query))
raise Exception('Error in spotify api for {}'.format(query))
type_plural = type + 's'
if response.json()[type_plural]['total'] > 0:
return response.json()[type_plural]['items'][0]
else:
return None
Essentially, it’s just a call to the API endpoint /v1/search. The only two odd parts are how the query string is formatted (it looks something like this: Artist:Arist Name Song:Song Name) and the memory.cache decorator.
The decorator comes from joblib and is basically an easy way to make sure that I don’t fetch this information more than once per song no matter how many times I call this method. It will save the results and return them directly for any future calls. To initialize it, all I have to do is run memory = joblib.Memory(cachedir = 'cache', verbose = 0) at the top of my code.
Now that we have a way of looking up songs, lets write a few more helper methods to read from the iTunes library. The first thing that you have to do is check the Advanced setting to ‘Share iTunes Library XML with other applications’:
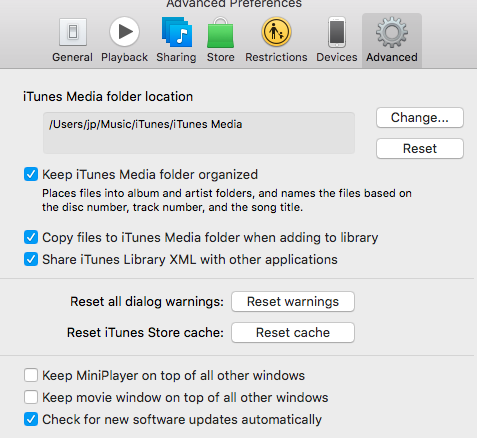
This will make the file iTunes Library.xml / iTunes Music Library.xml (it changed between Yosemite and El Capitan) available in your iTunes folder. This is a plist file which means the built in plistlib can read it directly:
path = os.path.expanduser('~/Music/iTunes/iTunes Music Library.xml')
with open(path, 'rb') as fin:
ITUNES_LIBRARY = plistlib.load(fin)
We can then use this directly to read in information about any given track that we have in our library.
@memory.cache
def get_track(track_id):
'''Get a track by ID.'''
logging.debug('get_track({})'.format(track_id))
track = ITUNES_LIBRARY['Tracks'].get(str(track_id), None)
if not track:
return None
def remove_parentheticals(s):
return re.sub(r'\s+[\(\[].*[\)\]]', '', s)
spotify_data = spotify_search('track',
artist = remove_parentheticals(track['Artist']),
track = remove_parentheticals(track['Name']),
)
if spotify_data:
track.update(spotify_data)
return track
Essentially, we pull the Tracks object out of the iTunes library which is indexed by a track_id. There’s one kind of weird part here in that the Tracks object uses numeric strings as keys while the Playlists tracks (see below) are returned as ints. Thus the cast. We take the information from iTunes and then try to look up the song in Spotify. If the search returns, we shove the two objects together. If not, we return just the iTunes information and deal with that later.
Next, we want to look up playlists:
def get_playlists():
'''
Return all playlists for the current user.
Each will be of the form:
{'name': '{playlist_name}', 'tracks': [...]}
'''
for playlist in ITUNES_LIBRARY['Playlists']:
if any(key in playlist and playlist[key] for key in ['Master', 'Movies', 'TV Shows', 'Podcasts', 'iTunesU', 'Audiobooks']):
continue
yield {
'name': playlist['Name'],
'tracks': [
get_track(track['Track ID'])
for track in playlist['Playlist Items']
if get_track(track['Track ID'])
]
}
This is a bit odd, since there are many different kinds of playlists in the iTunes library, not all of which have the same keys. With a bit of experimentation, I found that the list of keys above are the ones we want to avoid. Other than that, we will yield each playlist along with a list of track objects from get_track. This is why I cached those results, since a track can (and often will be) in multiple playlists and we don’t want to re-fetch the track information if that’s the case.
That’s actually the lion’s share of what I need. All that’s left is the code to create / find Spotify playlists and then add the songs to them. For that, I’m going to use the spotipy library rather than directly dealing with the endpoints. For the most part, it really helps with the OAuth tokens. All we have to do to create a Spotipy client is this:
token = spotipy.util.prompt_for_user_token(
os.env['SPOTIFY_USERNAME'],
client_id = os.env['SPOTIFY_CLIENT_ID'],
client_secret = os.env['SPOTIFY_CLIENT_SECRET'],
redirect_uri = os.env['SPOTIFY_REDIRECT_URI'],
scope = os.env['SPOTIFY_SCOPE'],
)
sp = spotipy.Spotify(auth = token)
You have to create a Spotify App, but that’s straight forward enough and free. The first time this is run, you will have to okay the permissions in your web browser, but after that it will keep track of your Spotify API token and will run transparently.
I’m going to use that to write one more helper method:
def get_spotify_playlist(title):
'''Get either an existing or new playlist by title.'''
playlists = sp.user_playlists(sp.me()['id'])['items']
for playlist in playlists:
if title == playlist['name']:
return playlist
return sp.user_playlist_create(sp.me()['id'], title)
The article that inspired this code only used the user_playlist_create method, but that will create a new playlist on each run. Instead, we want to check if there’s already a playlist matching the name that we’re trying to create. If so, return that playlist. If not, create a new one to return.
Now we have everything we need. We can write a script that will loop through any iTunes playlists specified on the command line (or all of them if none are specified) and sync them to Spotify:
for playlist in get_playlists():
if len(sys.argv) > 1 and playlist['name'] not in sys.argv:
continue
spotify_playlist = get_spotify_playlist('iTunes - {}'.format(playlist['name']))
uris = [
track['uri'] for
track in playlist['tracks']
if 'uri' in track
]
def chunks(items, size):
for start in range(0, len(items), size):
yield items[start : start + size]
for uri_chunk in chunks(uris, 100):
sp.user_playlist_add_tracks(sp.me()['id'], spotify_playlist['id'], uri_chunk)
I did hit one interesting temporary roadblock in that the Spotify API cannot accept more than 100 URIs at a time, but the chunk method took care of that. One thing that is nice is that the list of songs in a playlist form a set. So it doesn’t matter if we add the same song to a playlist more than once, it will still only exist a single time. That’s pretty cool!
And that’s it. A quick run (it took a few minutes to get all of the information for the 500 songs I have in my iTunes library) and I now have a Spotify playlist for each of my iTunes ones. It’s not perfect. There are still a few artists that are on Apple Music but not Spotify. But for a stopgap and when I’m on computers that don’t have my iTunes library, it works pretty well. I’ll probably set this up to run periodically, just so I always have my playlists relatively up to date.