Programming Praxis’ new challenge(s) are to write three different list algorithms three times, each with a different runtime complexity. From their first post last week we have list intersection and union and from a newer post yesterday we have the difference of two lists. For each of those, we want to be able to write an algorithm that runs in O(n2) time, one that runs in O(n log n), and finally one that runs in O(n). It turns out that it’s more of an exercise in data structures than anything (although they’re all still technically ’list’ algorithms), but it’s still interesting to see how you can achieve the same goal in different ways that may be far more efficient.
Since all three of the basic algorithms (intersection, union, and difference) are actually rather similar, I’m going to start with the three different runtimes first. Like my recent Project Euler posts, I’ll be writing the code in both Racket and Python to help those that read one language but not the other (although I would highly recommend that you learn both actually, they each have definite strengths). If you’d like to see the full code for each algorithm, you can see it here: python, racket
First, let’s start with the slowest but most likely easiest to understand algorithm. Since we’re doing list intersection, we want to only return the elements in both lists. To do that, we want to start by looping over one list. For each element in that last, scan through the second list. If the element is in both, return it, otherwise, skip it. This ends up being O(n2) because for each element in one list (O(n)), you have to loop over the other list (also O(n)). Since the loops are nested, you multiply the runtimes, resulting in O(n2).
Starting with the Python version (note that Python’s in operator on lists loops over the list to check for inclusion):
def intersection_loops(ls1, ls2):
'''Calculate the intersection of two lists using nested loops.'''
result = []
for e in ls1:
if e in ls2:
result.append(e)
return result
(Yes, this could be written in a single line using Python’s list comprehension as return [e for e in ls1 if e in ls2]. In this case, I’m going for clean code over the shortest version.)
Next, we have the Racket version (in much the same way, member is linear):
; Calculate the intersection of two lists using nested loops.
(define (intersection-loops ls1 ls2)
(let loop ([ls1 ls1])
(cond
[(null? ls1) '()]
[(member (car ls1) ls2)
(cons (car ls1) (loop (cdr ls1)))]
[else
(loop (cdr ls1))])))
This could be shortened significantly using Racket’s for/list macro:
(define (intersection-loops ls1 ls2)
(for/list ([e (in-list ls1)]
#:when (member e ls2))
e))
This will work here and on the third case, but we’ll need to write the loops explicitly in the next (pre-sorted) case.
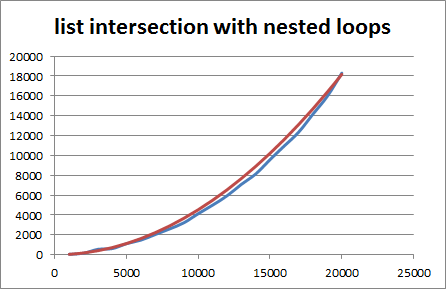
When you run it on some randomly generated lists, the result is quite obviously quadratic (the blue line is the runtime, the red line is a quadratic fit):
Next, we want to improve the time to O(n log n). Any time that you see a runtime like that, you should immediately think ‘sort’ (or trees, but not in this case) as the best sorting algorithms all have that runtime. In this case, we have to change the algorithm somewhat, but the basic idea is to first sort the lists. Then, you only have to compare the first elements against each other, basically zipping them together.
That basic idea in Python:
def intersection_sort(ls1, ls2):
'''Calculate the intersection of two lists by sorting them first.'''
ls1 = sorted(ls1)
ls2 = sorted(ls2)
result = []
i, j = 0, 0
while True:
if i >= len(ls1):
break
elif j >= len(ls2):
break
elif ls1[i] < ls2[j]:
i += 1
elif ls1[i] > ls2[j]:
j += 1
else: # ==
result.append(ls1[i])
i += 1
j += 1
return result
For intersection, if either list runs out, we’re done. There will be no more matched elements. If either first element is smaller than the other, skip past that one. As soon as they’re both equal, we have a match. Return it and keep going. The other two (union and difference) are much the same, see the full code (python, racket) for more details.
And here’s the Racket version:
(define (intersection-sort ls1 ls2)
(let loop ([ls1 (sort ls1 <)]
[ls2 (sort ls2 <)])
(cond
[(null? ls1) '()]
[(null? ls2) '()]
[(< (car ls1) (car ls2))
(loop (cdr ls1) ls2)]
[(> (car ls1) (car ls2))
(loop ls1 (cdr ls2))]
[else
(cons (car ls1) (loop (cdr ls1) (cdr ls2)))])))
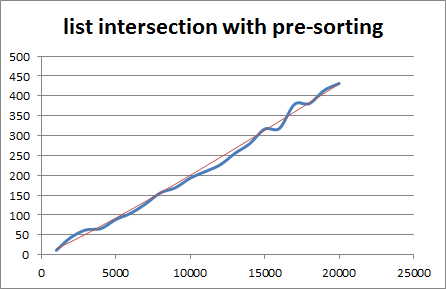
If we graph this one against O(n log n), we find that the graph isn’t nearly as nice. Mostly, that’s due to the relatively small times we’re using. I also tried using larger lists, but garbage collection became a significant problem. Again, the blue is runtime and the red is the expected value.
Finally, the fastest version. The goal here is O(n). Since we have to loop over the lists at least once, that’s going to be the fastest we can get. Since we don’t have any more room to breathe as it were, we need an O(1) sort of algorithm. The first thing that comes to mind then is a hash. Hashes will gives us both O(1) insertion and selection, so it sounds like exactly what we need. Actually, the change from the first set (with nested loops) is only a line or two of code in each. In the Python version, we’ll still be using in, but we want to build a set first (which is stored using hashing):
def intersection_hash(ls1, ls2):
'''Calculate the intersection of two lists using a hash.'''
ls2_set = set(ls2)
result = []
for e in ls1:
if e in ls2_set:
result.append(e)
return result
And similarly for Racket, we will be using a hash built using for/list. For that, we want to return two values, the key and the value. We don’t care what the values are, so we’ll just insert #t. Then we can use hash-has-key? to do the lookup:
; Calculate the intersection of two lists using a hash.
(define (intersection-hash ls1 ls2)
(define ls2-hash (for/hash ([e2 (in-list ls2)]) (values e2 #t)))
(let loop ([ls1 ls1])
(cond
[(null? ls1) '()]
[(hash-has-key? ls2-hash (car ls1))
(cons (car ls1) (loop (cdr ls1)))]
[else
(loop (cdr ls1))])))
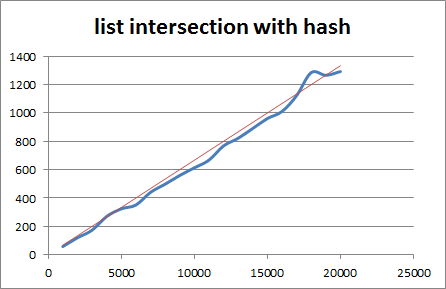
Similiarly to the sorted case, the timing (blue line) isn’t perfect, but it’s quite clearly linear (the red line):
ANd that’s it. I’m not actually going to include the code for union or difference as it’s basically the same with a few minor tweaks. You can see it in its fully comment entirety here: python, racket