They say a picture is worth a thousand words:
One Thousand Words
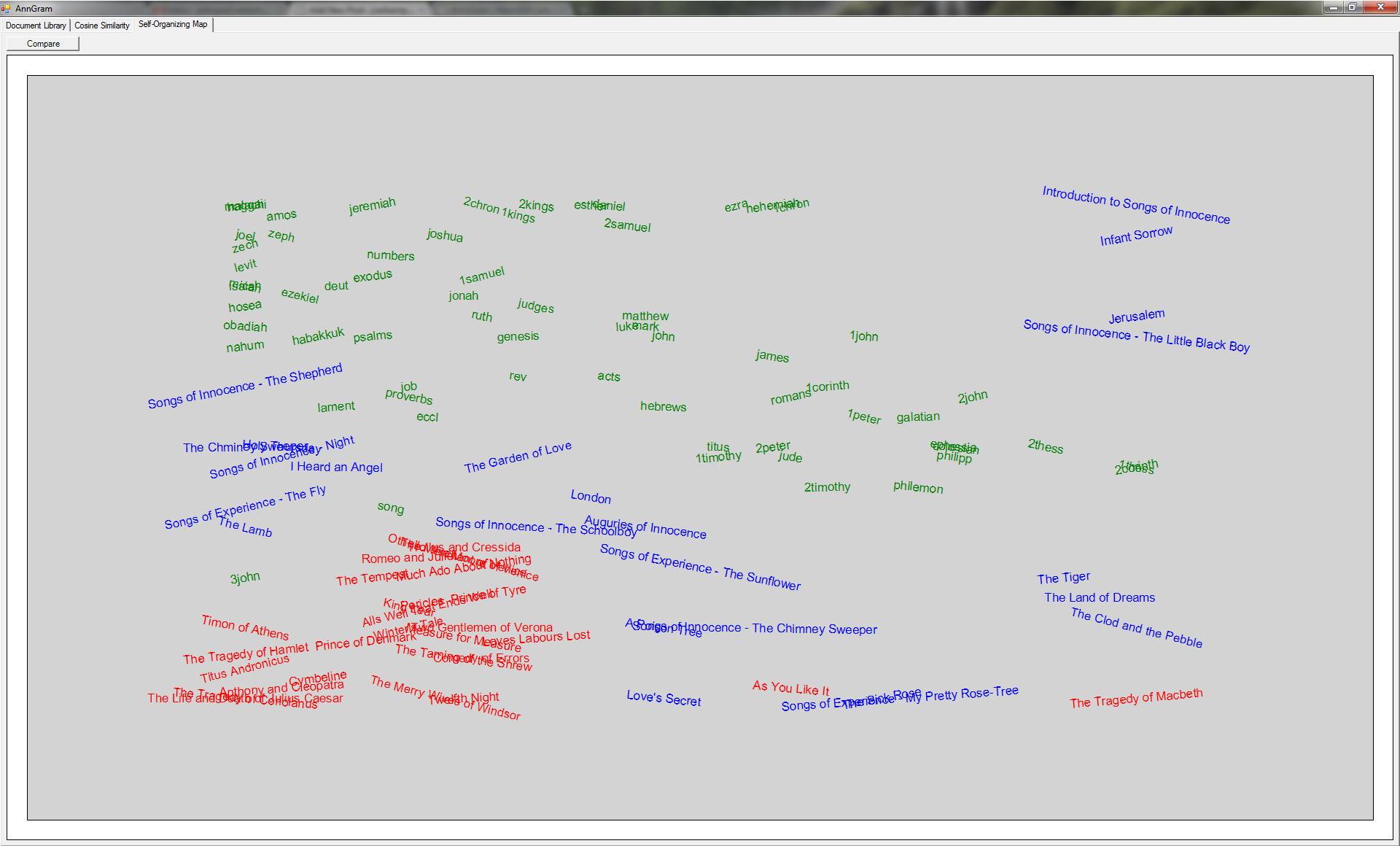
Overview
What you are seeing is the results of applying a Self-Organizing Map to the nGram vectors generated from a series of documents. The author for each document is stored so as to color the final documents, but that information is not given to the algorithm in any way. In the above picture, red is Shakespeare, blue is William Blake, and green is the Bible. As you can see, the Self-Organizing Map did a surprisingly awesome job at classifying the documents. With a few exceptions, all of Shakespeare’s works are in the bottom left, the bible is in the top left, and William Blake is between them. Due to random nature of the core of the algorithm, the results can be different on different iterations, but are still generally impressive.
Another Thousand Words

This time the groups are more defined. One thing that I would like to look into is why The Tragedy of Macbeth (and As You Like It to a lesser extent) doesn’t show up in the larger Shakespeare section. One feature of note in this screenshot is the combination of the disabled Compare button and the current error display. What this means is that the map is currently being generated. With the current multi-threaded layout, it is possible to generate the map and watch it as it optimizes.
Construction of the nGram Vector
The original plan was to find the most common nGrams in the English language and use their frequencies to build a vector representing each document; however, the problem with this approach was finding the most common nGrams. To solve this, I loop through all of the documents being used in the map, adding the most common nGram not in the list for each until a long enough vector has been generated. For the purposes of the experiment, the size of this vector is currently 100.
Future Plans
First, it would be most useful to determine if feeding nGrams to the Self-Organizing Map is actually an improvement over other possibilities. I’m currently looking into literature to determine a basis for comparison. Alternatively, I would like to see if applying k-means clustering to the nGram vectors would work as well as the Self-Organizing maps.
Second, I would like to add a little more customization to the tab: the ability to choose the length of the nGrams to use (currently 4), the size of the comparison vectors (currently 100), and the error threshold (currently 0.0001).