Overview
For now, I’ve chosen to work with C# Neural network library. It was the easiest to get off the ground and running, so it seemed like a good place to start.
Measure of Similiarity
To complement the Cosine Similarity that I discussed earlier, the Neural Networks will be designed to take in two nGram documents (or authors) and return a number representing how similar the two are. To that end, my initial plan is to determine the top 100 (for now) nGrams throughout all of the documents that I have and lock those as the inputs to the neural networks. Then, the frequency of each of these will be fed in for both documents and a single number (the similarity) will be returned. To train the networks, documents that should be the same will be forced towards a 1.0 and documents that should be different will be forced towards a 0.0.
**Results **
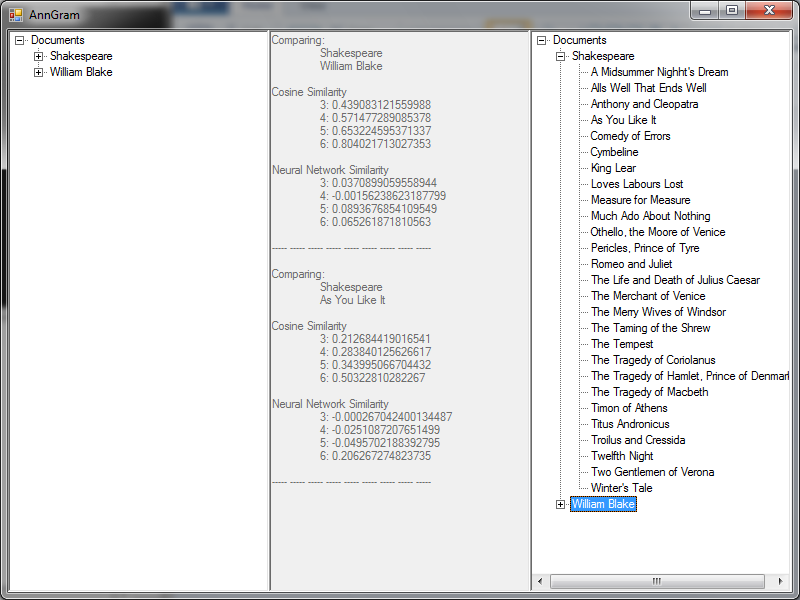
As you can see in the above image, the results are less than encouraging. With the exception of 6-grams, the results are the same (nearly 0) for all of the examples, including both documents that should have been similar and ones that should not have been.
I expect that I either do not have enough information to feed to the neural networks or that the method that I described above is not well tuned to the problem at hand. I intend to spend the next week looking into the problem. http://franck.fleurey.free.fr/NeuralNetwork/